

详细介绍
工具简介
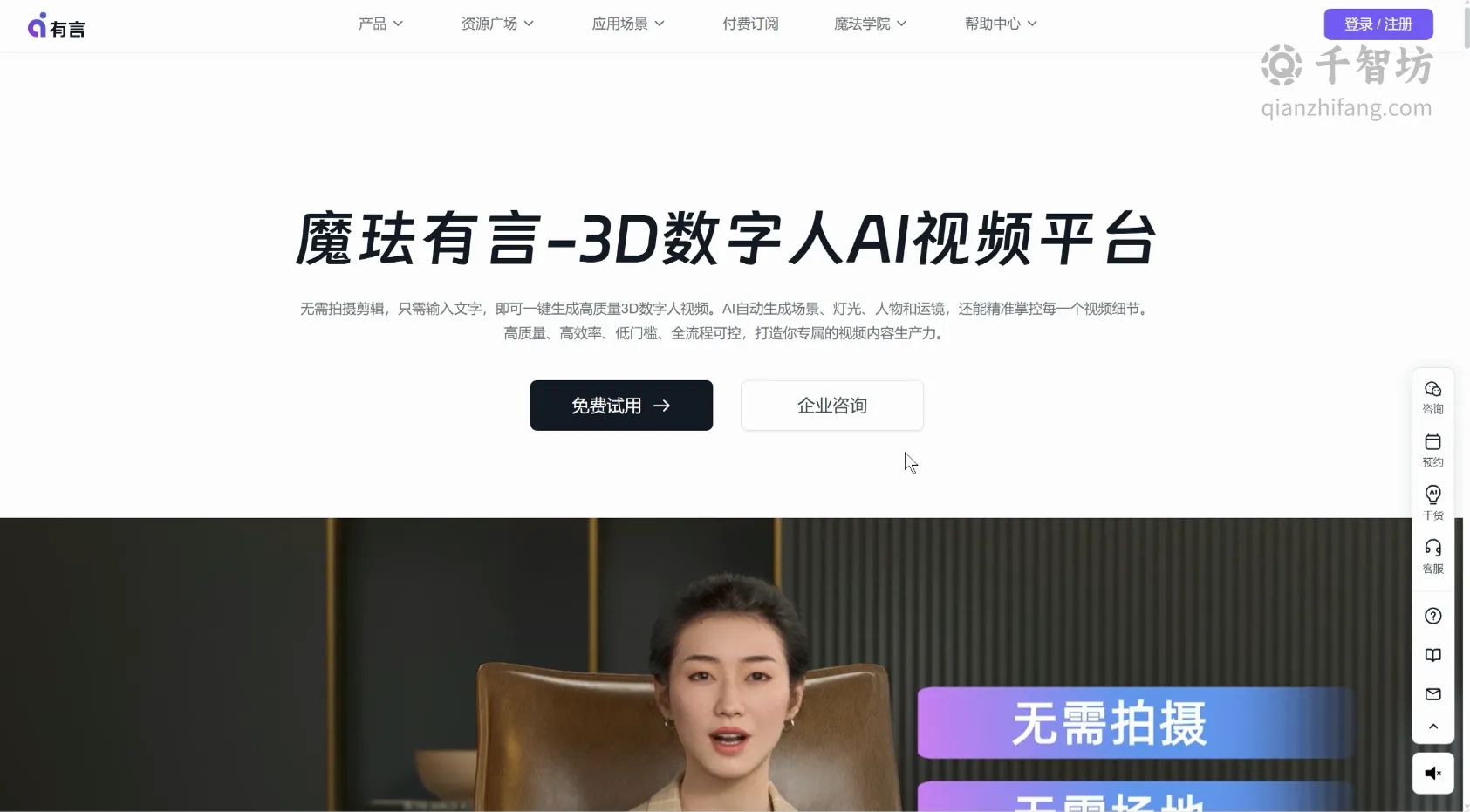
有言(Youyan)是由魔珐科技(Xmov)推出的一款面向企业和个人的3D AI视频生成与数字人创作平台。该平台依托于魔珐科技在计算机视觉、计算机图形学和深度学习领域的深厚积累,旨在帮助用户无需专业动画或视频制作技能,即可快速创建逼真的3D数字人分身,并驱动其生成高质量的讲解、演示或营销视频。
有言的核心价值在于将复杂的3D角色建模、动作捕捉、语音合成和口型同步等环节整合为一条自动化的生产流水线。用户只需提供文本脚本或上传音频,系统即可自动生成由数字人主播演绎的视频内容。这使得内容创作者、教育工作者、企业营销人员等能够以极低的成本和时间投入,获得以往需要专业团队和昂贵设备才能完成的视频作品。
主要功能
3D数字人创建与定制
有言提供了丰富的数字人形象库,涵盖不同性别、年龄、风格和职业装扮的预设角色。用户可以根据品牌调性或内容场景,选择基础形象并进行二次定制,包括调整发型、服装、配饰等细节。平台支持高精度的面部特征和身体比例调节,确保数字人形象既美观又具备真实感。此外,用户还可以上传自己的照片或扫描数据,生成个性化的数字分身,实现真正的“为自己代言”。
智能语音与口型同步
平台内置了先进的文本转语音(TTS)引擎,支持多种语言和方言的语音合成。用户只需输入文字脚本,系统即可自动生成自然流畅的语音,并精确驱动数字人的口型、面部表情和头部动作,实现音画同步。有言还支持用户上传自定义的录音文件,系统会分析音频特征并自动匹配数字人的唇形,让数字人的“表演”更加贴合真人原声的节奏和情绪。
场景与镜头自动化编排
有言内置了多种预设的3D虚拟场景,如演播室、办公室、教室、户外景观等,用户可根据内容主题一键切换。平台采用智能镜头语言,能够根据脚本的段落结构和情感起伏,自动生成推拉摇移、特写、中景等镜头切换效果,无需用户手动调节关键帧。对于高级用户,有言也提供了手动调整机位、灯光和背景元素的权限,实现更精细的创作控制。
动作与手势驱动
为了让数字人表现得更自然,有言集成了AI动作生成模块。系统会根据脚本内容的语境(如讲解、提问、强调重点)自动匹配相应的手势和身体动作。例如,在介绍产品特点时,数字人会自然地做出指向、展示等手势;在表达欢迎或感谢时,会配合鞠躬或点头动作。这种动态表现力极大地提升了视频的观看体验和信息传达效率。
批量渲染与高效导出
有言支持云端渲染,用户提交视频生成任务后,无需占用本地计算资源,即可在短时间内获得高清视频文件。平台支持多种分辨率输出(包括1080P和4K),并提供MP4、MOV等常见格式。对于需要制作系列课程或批量营销素材的用户,有言提供了模板管理和批量生成功能,可以一键替换脚本中的关键信息(如姓名、日期、产品名称),实现大规模个性化视频的快速生产。
多语言与国际化的支持
针对有出海需求或需要制作多语言版本内容的企业,有言提供了多语言TTS支持,包括中文、英语、日语、韩语、西班牙语、法语等主流语言。数字人的口型会根据所选语言自动适配,确保在不同语言下都能保持自然的发音视觉效果。这一功能使得跨国企业能够高效地制作本地化营销视频,而无需为每种语言重新录制真人视频。
应用场景
有言的应用场景非常广泛,几乎覆盖了所有需要“人物出镜”的视频制作需求。在在线教育领域,教师可以创建自己的数字分身,用于录制课程视频、微课和知识科普内容,无需反复面对镜头重录,大大提升了课程制作效率。在企业培训场景中,HR或培训部门可以快速生成标准化的员工培训视频,确保所有分支机构接收到一致的信息,同时数字人的形象可以设计为统一的虚拟讲师,强化品牌认知。
在市场营销方面,营销团队可以利用有言制作产品介绍、促销活动预告、客户案例分享等视频,数字人主播可以24小时不间断地“出镜”,且无需支付额外的出场费用。对于自媒体创作者和短视频博主,有言提供了一种全新的内容创作方式,他们可以创建虚拟IP形象,打造独特的个人品牌,甚至让数字人代替自己进行直播或日常内容更新,从而解放真人主播的时间,专注于创意策划和互动运营。
此外,有言在企业宣传、政企服务、博物馆导览、虚拟偶像运营等领域也有巨大的应用潜力。例如,在金融行业,银行可以使用数字人客服来讲解理财产品;在政务服务中,数字人可以担任政策解读员,提供统一、准确的信息发布。
产品优势
与传统的真人视频拍摄或基于2D图像的数字人工具相比,有言的核心优势在于其全3D化的数字人资产和高度自动化的生产流程。传统的真人拍摄受制于场地、设备、演员档期和拍摄成本,而2D数字人工具往往只能提供固定的头部动作和有限的背景切换,缺乏立体感和动态表现力。有言通过3D建模和实时渲染技术,赋予了数字人完整的身体动作、多变的角度和沉浸式的3D场景,使得最终视频的质感和专业度远超2D方案。
另一个显著优势是低门槛与高产出。用户无需学习任何3D建模、动画或视频编辑软件,仅需通过网页浏览器登录平台,即可在几分钟内完成从脚本到视频的全流程创作。这对于非技术背景的内容创作者尤其友好。同时,云端渲染和批量生成能力使得大规模视频生产成为可能,极大地缩短了项目周期。
使用方法
使用有言创建视频的流程非常直观,大致分为以下几步:
- 登录与创建项目:访问有言官网,通过微信扫码登录,绑定账号后进入工作台。点击“新建项目”开始创作。
- 选择或定制数字人:从形象库中选择一个预设数字人,或上传照片生成个人分身。根据需要调整形象细节,如服装、发型等。
- 输入脚本与语音:在文本框中输入视频脚本内容,选择语言和语音风格(如温柔、热情、专业)。也可以上传录制好的音频文件。
- 选择场景与布局:从场景库中选择合适的虚拟背景,或上传自定义背景图。系统会自动根据脚本长度和内容调整镜头。
- 预览与调整:点击预览,观看数字人演绎的效果。如果对动作、表情或节奏不满意,可以进行局部微调。
- 生成与导出:确认无误后,点击“生成视频”,系统将提交至云端渲染。渲染完成后,即可下载高清视频文件。
整个流程通常只需几分钟到十几分钟,具体时间取决于脚本长度和视频分辨率。
技术特点
有言背后的技术核心是魔珐科技自研的全栈式3D数字人技术,包括高精度3D扫描重建、基于深度学习的动作捕捉与迁移、以及实时渲染引擎。在语音驱动口型方面,有言采用了端到端的神经网络模型,能够直接根据音频波形预测面部肌肉的运动参数,从而实现毫秒级的精准同步。在动作生成上,系统利用大量真人演讲和表演数据训练了动作生成模型,使得数字人的手势、姿态和微表情更加丰富和自然。
此外,有言在渲染管线中集成了全局光照和物理材质系统,使得数字人的皮肤、头发和衣物在虚拟场景中呈现出逼真的光影效果。这一技术虽然增加了计算量,但通过云端GPU集群的分布式渲染能力,保证了用户在合理时间内获得高质量的最终输出。
核心功能
优缺点分析
适用人群
常见问题





